Излезе версия 1.0 на SEOSpyder. SEOSpyder е оригинален български SEO tool за Mac OSX, разработка на Mobilio, който имах възможност да тествам последните месеци. В момента ми е основен инструмент за анализ на сайтове под Мак. За съжаление май не се предвижда версия за Windows ")
Определено цената от 99 USD за продукта е доста разумна за възможностите, които предлага - https://itunes.apple.com/app/seospyder-pro/id674460993?mt=12&affId=2094294
SEOSpyder is neat and small crawling software for Mac OSX which provides its users with in-depth seo data and features of a particular website. With it you can easily scan, trace and analyse every single link on your website which makes it a quite powerful tool for dealing with 404s and any other type of errors and mistakes which would be punished by the web crawlers. Moreover the product provides you with information not only for the HTMLs but for the images, css and javascript files and a lot of metadata – source paths, alt and anchor texts, rel attributes and others.
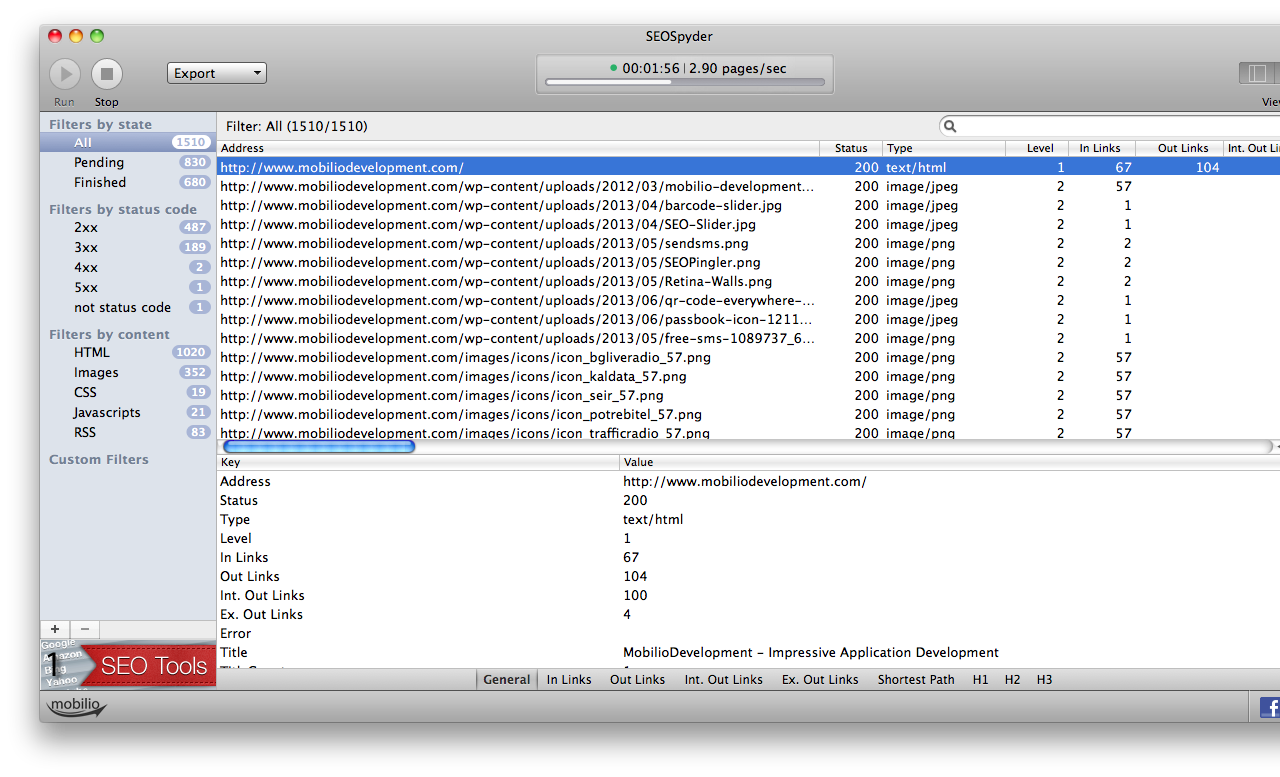
Start, save and export a crawl of a site
Hit Run or File>New, choose one from the 18 crawling agents (very useful if you have both mobile and desktop versions of your site) and let the analysing begin. The already processed links will show up in the “Finished” filter and the ones that wait on the queue – in the “Pending”. The progress of the scan, the scanning speed and the elapsed time are displayed in the top panel. Once you hear the nice melody and the spider is ready export the results either as an HTML report, csv file, sitemap xml file or GraphVz file. If you have paused the crawl and want to start a new one, go to File>Clear and then File>New or directly to the File>New.
Tip: If you have just finished a 2+ hour crawl you might want to save all the retrieved data about your site for later usage in the native file format of SEOSpyder- *.seospyder. Then you can load it instantaneously at any time and examine it as if it has just been harvested. If you choose to export the data as a Report, Sitemap or GraphVz file, SEOSpyder will export all the examined links. However if you want to export only a particular filter – right click on it and choose “Export to csv”.
Custom user-made filters – the true analytical power of SEOSpyder
Filters are what will make you fall in love with SEOSpyder. The default 13 filters are in the right panel and are sorted in categories:
Filters by state: All, Pending, Finished;
Filters by content: HTML, Images, CSS, Javascripts, RSS;
Filter by status code: 2xx, 3xx, 4xx, 5xx, not status code;
Custom Filters: —
The last one – Custom Filters is where the true power of the SEOSpyder comes from. Find all the pages whose title contain the word “QR”, have PNG images on them and have response time above 3 sec or find all the pages with one and the same author and external outlinks more than 50. The combinations are basically numerous and the more you think about it, the more you realize what are the true capabilities of the SEOSpyder.
Tip: The subject about the custom filters is quite vast and can’t be fully comprised here. For more information and useful examples regularly check our blog or the video tutorials tab which is currently “under construction”
SEOSpyder provides elaborated and in-depth insight of your webpages
The up (main) window distributes to the user the following 36 key and unique SEO attributes about every single link in your site:
Address
Status code
Content Type
Level
In Links
Out Links
Int. Out Links
Ext. Out Links
Error
Title
Title Length
Titles Count
Meta Desc.
Meta Desc. Length
Meta Desc. Count
Author
Publisher
Canonical
Size
Duration
Date
Charset
Server
Base
Meta Keywords
Meta Keywords Length
Meta Keywords Count
H1 Count
H2 Count
H3 Count
Open Graph Title
Open Graph Type
Open Graph URL
Open Graph Image
Facebook Page Id
Facebook App Id
Anchor text
The interface is not only simple and intuitive but flexible as well. The filters and the bottom window can be hidden from the “View” buttons. Furthermore you can always rearrange the default order of the columns or even hide some of them by right clicking and choosing “Show View Options”. What is more right clicking on any of the links will reveal you quite a few handy and useful functionalities like:
Copy the URL or Open it in browser;
Auditing the link with SEOAuditor;
Pinging it with SEOPingler;
Validating it with the W3 validator;
Checking the loading speed of the page in WebPageTest, PingDom, Google page speed or GTmetrix;
View the page in InterArchive;
View the page in responsinator.com – credential for mobile sites;
Above the columns there is a search bar for further browsing the filters. Once a sequence of characters is entered the application will give you only the links that contain this particular sequence. If you are at the 2xx filter and enter “qrencoder” it will give you all the links that are Ok and contain the word. Moreover if you switch between the filters – for example go to the 3xx – the search will still be applied.
Tip: If you have searched the results from a particular filter (3xx) and choose to export this filter as csv file (by right clicking on it) the searched 3xx will be exported not all 3xx.
Once you have selected a link in the up (main) window the bottom window will provide you with 9 different tabs giving you almost the same information as in the up one, but structured and in greater details:
General – the same seo keys and values as in the up window but more concise;
In, Out, Internal Out, External Out Links – all the links from this type for the particular page and their metadata;
Shortest Path – the shortest path to a particular page from the root directory;
H1, H2, H3 – all the heading tags on the page selected in the up window and their lengths;
Tip: The context menu in the bottom window is almost the same as in the up one – the only difference is that if you want to examine a link from one of the tabs in the bottom window you can choose “GoTo”, jump to it in the up window and examine its details and features.
Custom Filters Explained
Address – returns all links that are/ are not/ begin with/ end with/ contain a particular string;
Is External link – returns all links that are/are not external;
Content Type – returns all links containing/ not containing a particular content type (text/html, image/png, text/javascript);
State – returns all links which are/ are not at a particular state (New, Finished, Pending);
Duration – returns all links that have loading time greater/less than the inputed by the user;
Date – returns all links that have date before/after/ exactly the same as the inputed by the user;
Size – returns all links leading to files that have less/ greater size than the inputed by the user;
Status Code - returns all links with status code less/ greater/ exactly the same as the inputed by the user;
Level - returns all links with depth level (starting at the root dorectory) less/ greater/ the same as the inputed by the user;
Anchor – returns all links with anchor text that is/ is not/ begins with/ ends with/ contains a particular string;
Server - returns all links that are on a server that is/ is not/ begins with/ ends with/ contains a particular string;
Error – returns all links that have given a particular error while communicating with the server like: “server timeout”, “unsupported url”;
Charset – even though the most common charset is the utf-8 there are others like ISO-8859-1 which you might want to filter out;
Base - The <base> tag specifies the base URL/target for all relative URLs in a document. With this filter you can get all pages that have/ don’t have a particular base URL;
Canonical – when having several pages on your site with the same content the rel=”canonical” specifies which of these pages should not be indexed. Alongside with the rel attribute of the <link> tag which is put in the <head> section of the page there is a href attribute which shows the main link/the one to be indexed.
Title – gives you all pages whose titles are/are not/ contain particular string
Title Count – if you want to see all pages with for example more than one or less then 3 title tags then this is the filter for you
Title Lenght – too long or too short articles are not very good seo practice – use this filter and fix the problem
Meta Description – if you want to examine all pages whose meta description contains particular word/phrase then this is the filter for you.
Meta Description Count – find all pages with more then one or none meta description tags
Meta Description Length – the meta description is recommended to be no more than 140 characters. Check out whether your site has pages that do not satisfy this condition;
Meta Keywords - if you want to examine all pages whose meta keywords tag contains a particular word/phrase then this is the filter for you.
Meta Keywords Count - find all pages with more then one or none meta keywords tags
Meta Keywords Length - the meta keywords tag is recommended to be no more than 10 words (relatively 100 characters). Check out whether your site has pages that do not satisfy this condition;
In Links count – Check out whether you have pages with too small or too high number of in links (links pointing to that page)
Out Links count - Check out whether you have pages with too small or too high number of out links (links on a page that point out to other pages)
Internal Out Links count - Check out whether you have pages with too small or too high number of internal out links (links from a page that point to other pages In your site)
External Out Links count - Check out whether you have pages with too small or too high number of external out links (links from a page that point to other pages Outside your site)
Open Graph Title – Open Graph Meta tags help you customize the way your page would appear in Facebook as a graph object when shared. Check for pages with particular Open Graph Titles;
Open Graph Type - Open Graph Meta tags help you customize the way your page would appear in Facebook as a graph object when shared. The Type specifies what you are sharing – video, image, song, html page;
Open Graph URL - Open Graph Meta tags help you customize the way your page would appear in Facebook as a graph object when shared. Check for pages leading to one and a same object – one and a same URL;
Open Graph Image - Open Graph Meta tags help you customize the way your page would appear in Facebook as a graph object when shared. The Image tag is the URL of the little thumbnail that will represent your object/page in the graph;
Facebook Page Id – Integrate your social plug-ins with your Facebook brand page by embedding your Facebook Page Id in your web pages.
Facebook App Id - Integrate your social plug-ins with your Facebook application by embedding your Facebook App Id in your web pages.
Author – Google Authorship is very important from a SEO point of view. Connect your site with your G+ profile with the<link rel=”author” href=”…”> tag. The difference between the author and the publisher tags is that author is for people and publisher – for brands. Check out your site for mistakes with this filter;
Publisher - Google Authorship is very important from a SEO point of view. Connect your site with the G+ profile of your brand with the <link rel=”publisher” href=”…”> tag. The difference between the author and the publisher tags is that author is for people and publisher – for brands. Check out your site for mistakes with this filter;
H1 – get the pages with H1 tags, containing/ starting with/ ending with particular words/phrases
H1 count – pages with more than one H1 tags is quite big SEO mistake. Don’t make it or if you have already done it – fix it on time with this filter;
H1 length – Check for pages with too long or too small H1 tags;
H2 - get the pages with H2 tags, containing/ starting with/ ending with particular words/phrases
H2 count – Find all pages with more than necessary or none H2 tags;
H2 length - Check for pages with too long or too small H2 tags;
H3 - get the pages with H3 tags, containing/ starting with/ ending with particular words/phrases
H3 count - Find all pages with more than necessary or none H3 tags;
H3 length - Check for pages with too long or too small H3 tags;
In Links link type – Find all In links of a particular type – CSS IMG/ IMG/ SCRIPT/ LINK/ HREF/ IFRAME/ FRAME/ BACKGROUND/ REDIRECT;
In links Anchor text – Get all In links with a particular anchor text;
In links Alt text – Returns all In links whose alt text contains/ starts with/ ends with a particular string
In Links Rel attr – Find all In links with a particular Rel attr – canonical, nofollow, noindex, …;
In Links link type length – Retrieve all In links with a particular length of the link type column;
In links Anchor text length - Find all In links with too long or none Anchor text and fix them
In links Alt text length - Alt text is recommended to be no more than 100 characters. Find all In links with too long or none Alt text and fix them;
In Links Rel attr length - This filter is useful for finding In links with no rel attr;
Identical In Links count – Get pages with particular number of Identical In Links. Identical links are links that have exactly the same attribute values – link type, anchor and alt text or rel attribute. Even if one of these attributes are slightly different then the links won’t be considered identical;
Out Links link type - Find all Out links of a particular type – CSS IMG/ IMG/ SCRIPT/ LINK/ HREF/ IFRAME/ FRAME/ BACKGROUND/ REDIRECT;
Out links Anchor text - Get all Out links with a particular anchor text;
Out links Alt text - Returns all Out links whose alt text contains/ starts with/ ends with a particular string
Out Links Rel attr - Find all Out links with a particular Rel attr – canonical, nofollow, noindex, …;
Out Links link type length - Retrieve all Out links with a particular length of the link type column;
Out links Anchor text length – Find all Out links with too long or none Anchor text and fix them;
Out links Alt text length - Alt text is recommended to be no more than 100 characters. Find all Out links with too long or none Alt text and fix them;
Out Links Rel attr length - This filter is useful for finding Out links with no rel attr;
Identical Out Links count - ...
Определено цената от 99 USD за продукта е доста разумна за възможностите, които предлага - https://itunes.apple.com/app/seospyder-pro/id674460993?mt=12&affId=2094294
SEOSpyder is neat and small crawling software for Mac OSX which provides its users with in-depth seo data and features of a particular website. With it you can easily scan, trace and analyse every single link on your website which makes it a quite powerful tool for dealing with 404s and any other type of errors and mistakes which would be punished by the web crawlers. Moreover the product provides you with information not only for the HTMLs but for the images, css and javascript files and a lot of metadata – source paths, alt and anchor texts, rel attributes and others.
Start, save and export a crawl of a site
Hit Run or File>New, choose one from the 18 crawling agents (very useful if you have both mobile and desktop versions of your site) and let the analysing begin. The already processed links will show up in the “Finished” filter and the ones that wait on the queue – in the “Pending”. The progress of the scan, the scanning speed and the elapsed time are displayed in the top panel. Once you hear the nice melody and the spider is ready export the results either as an HTML report, csv file, sitemap xml file or GraphVz file. If you have paused the crawl and want to start a new one, go to File>Clear and then File>New or directly to the File>New.
Tip: If you have just finished a 2+ hour crawl you might want to save all the retrieved data about your site for later usage in the native file format of SEOSpyder- *.seospyder. Then you can load it instantaneously at any time and examine it as if it has just been harvested. If you choose to export the data as a Report, Sitemap or GraphVz file, SEOSpyder will export all the examined links. However if you want to export only a particular filter – right click on it and choose “Export to csv”.
Custom user-made filters – the true analytical power of SEOSpyder
Filters are what will make you fall in love with SEOSpyder. The default 13 filters are in the right panel and are sorted in categories:
Filters by state: All, Pending, Finished;
Filters by content: HTML, Images, CSS, Javascripts, RSS;
Filter by status code: 2xx, 3xx, 4xx, 5xx, not status code;
Custom Filters: —
The last one – Custom Filters is where the true power of the SEOSpyder comes from. Find all the pages whose title contain the word “QR”, have PNG images on them and have response time above 3 sec or find all the pages with one and the same author and external outlinks more than 50. The combinations are basically numerous and the more you think about it, the more you realize what are the true capabilities of the SEOSpyder.
Tip: The subject about the custom filters is quite vast and can’t be fully comprised here. For more information and useful examples regularly check our blog or the video tutorials tab which is currently “under construction”
SEOSpyder provides elaborated and in-depth insight of your webpages
The up (main) window distributes to the user the following 36 key and unique SEO attributes about every single link in your site:
Address
Status code
Content Type
Level
In Links
Out Links
Int. Out Links
Ext. Out Links
Error
Title
Title Length
Titles Count
Meta Desc.
Meta Desc. Length
Meta Desc. Count
Author
Publisher
Canonical
Size
Duration
Date
Charset
Server
Base
Meta Keywords
Meta Keywords Length
Meta Keywords Count
H1 Count
H2 Count
H3 Count
Open Graph Title
Open Graph Type
Open Graph URL
Open Graph Image
Facebook Page Id
Facebook App Id
Anchor text
The interface is not only simple and intuitive but flexible as well. The filters and the bottom window can be hidden from the “View” buttons. Furthermore you can always rearrange the default order of the columns or even hide some of them by right clicking and choosing “Show View Options”. What is more right clicking on any of the links will reveal you quite a few handy and useful functionalities like:
Copy the URL or Open it in browser;
Auditing the link with SEOAuditor;
Pinging it with SEOPingler;
Validating it with the W3 validator;
Checking the loading speed of the page in WebPageTest, PingDom, Google page speed or GTmetrix;
View the page in InterArchive;
View the page in responsinator.com – credential for mobile sites;
Above the columns there is a search bar for further browsing the filters. Once a sequence of characters is entered the application will give you only the links that contain this particular sequence. If you are at the 2xx filter and enter “qrencoder” it will give you all the links that are Ok and contain the word. Moreover if you switch between the filters – for example go to the 3xx – the search will still be applied.
Tip: If you have searched the results from a particular filter (3xx) and choose to export this filter as csv file (by right clicking on it) the searched 3xx will be exported not all 3xx.
Once you have selected a link in the up (main) window the bottom window will provide you with 9 different tabs giving you almost the same information as in the up one, but structured and in greater details:
General – the same seo keys and values as in the up window but more concise;
In, Out, Internal Out, External Out Links – all the links from this type for the particular page and their metadata;
Shortest Path – the shortest path to a particular page from the root directory;
H1, H2, H3 – all the heading tags on the page selected in the up window and their lengths;
Tip: The context menu in the bottom window is almost the same as in the up one – the only difference is that if you want to examine a link from one of the tabs in the bottom window you can choose “GoTo”, jump to it in the up window and examine its details and features.
Custom Filters Explained
Address – returns all links that are/ are not/ begin with/ end with/ contain a particular string;
Is External link – returns all links that are/are not external;
Content Type – returns all links containing/ not containing a particular content type (text/html, image/png, text/javascript);
State – returns all links which are/ are not at a particular state (New, Finished, Pending);
Duration – returns all links that have loading time greater/less than the inputed by the user;
Date – returns all links that have date before/after/ exactly the same as the inputed by the user;
Size – returns all links leading to files that have less/ greater size than the inputed by the user;
Status Code - returns all links with status code less/ greater/ exactly the same as the inputed by the user;
Level - returns all links with depth level (starting at the root dorectory) less/ greater/ the same as the inputed by the user;
Anchor – returns all links with anchor text that is/ is not/ begins with/ ends with/ contains a particular string;
Server - returns all links that are on a server that is/ is not/ begins with/ ends with/ contains a particular string;
Error – returns all links that have given a particular error while communicating with the server like: “server timeout”, “unsupported url”;
Charset – even though the most common charset is the utf-8 there are others like ISO-8859-1 which you might want to filter out;
Base - The <base> tag specifies the base URL/target for all relative URLs in a document. With this filter you can get all pages that have/ don’t have a particular base URL;
Canonical – when having several pages on your site with the same content the rel=”canonical” specifies which of these pages should not be indexed. Alongside with the rel attribute of the <link> tag which is put in the <head> section of the page there is a href attribute which shows the main link/the one to be indexed.
Title – gives you all pages whose titles are/are not/ contain particular string
Title Count – if you want to see all pages with for example more than one or less then 3 title tags then this is the filter for you
Title Lenght – too long or too short articles are not very good seo practice – use this filter and fix the problem
Meta Description – if you want to examine all pages whose meta description contains particular word/phrase then this is the filter for you.
Meta Description Count – find all pages with more then one or none meta description tags
Meta Description Length – the meta description is recommended to be no more than 140 characters. Check out whether your site has pages that do not satisfy this condition;
Meta Keywords - if you want to examine all pages whose meta keywords tag contains a particular word/phrase then this is the filter for you.
Meta Keywords Count - find all pages with more then one or none meta keywords tags
Meta Keywords Length - the meta keywords tag is recommended to be no more than 10 words (relatively 100 characters). Check out whether your site has pages that do not satisfy this condition;
In Links count – Check out whether you have pages with too small or too high number of in links (links pointing to that page)
Out Links count - Check out whether you have pages with too small or too high number of out links (links on a page that point out to other pages)
Internal Out Links count - Check out whether you have pages with too small or too high number of internal out links (links from a page that point to other pages In your site)
External Out Links count - Check out whether you have pages with too small or too high number of external out links (links from a page that point to other pages Outside your site)
Open Graph Title – Open Graph Meta tags help you customize the way your page would appear in Facebook as a graph object when shared. Check for pages with particular Open Graph Titles;
Open Graph Type - Open Graph Meta tags help you customize the way your page would appear in Facebook as a graph object when shared. The Type specifies what you are sharing – video, image, song, html page;
Open Graph URL - Open Graph Meta tags help you customize the way your page would appear in Facebook as a graph object when shared. Check for pages leading to one and a same object – one and a same URL;
Open Graph Image - Open Graph Meta tags help you customize the way your page would appear in Facebook as a graph object when shared. The Image tag is the URL of the little thumbnail that will represent your object/page in the graph;
Facebook Page Id – Integrate your social plug-ins with your Facebook brand page by embedding your Facebook Page Id in your web pages.
Facebook App Id - Integrate your social plug-ins with your Facebook application by embedding your Facebook App Id in your web pages.
Author – Google Authorship is very important from a SEO point of view. Connect your site with your G+ profile with the<link rel=”author” href=”…”> tag. The difference between the author and the publisher tags is that author is for people and publisher – for brands. Check out your site for mistakes with this filter;
Publisher - Google Authorship is very important from a SEO point of view. Connect your site with the G+ profile of your brand with the <link rel=”publisher” href=”…”> tag. The difference between the author and the publisher tags is that author is for people and publisher – for brands. Check out your site for mistakes with this filter;
H1 – get the pages with H1 tags, containing/ starting with/ ending with particular words/phrases
H1 count – pages with more than one H1 tags is quite big SEO mistake. Don’t make it or if you have already done it – fix it on time with this filter;
H1 length – Check for pages with too long or too small H1 tags;
H2 - get the pages with H2 tags, containing/ starting with/ ending with particular words/phrases
H2 count – Find all pages with more than necessary or none H2 tags;
H2 length - Check for pages with too long or too small H2 tags;
H3 - get the pages with H3 tags, containing/ starting with/ ending with particular words/phrases
H3 count - Find all pages with more than necessary or none H3 tags;
H3 length - Check for pages with too long or too small H3 tags;
In Links link type – Find all In links of a particular type – CSS IMG/ IMG/ SCRIPT/ LINK/ HREF/ IFRAME/ FRAME/ BACKGROUND/ REDIRECT;
In links Anchor text – Get all In links with a particular anchor text;
In links Alt text – Returns all In links whose alt text contains/ starts with/ ends with a particular string
In Links Rel attr – Find all In links with a particular Rel attr – canonical, nofollow, noindex, …;
In Links link type length – Retrieve all In links with a particular length of the link type column;
In links Anchor text length - Find all In links with too long or none Anchor text and fix them
In links Alt text length - Alt text is recommended to be no more than 100 characters. Find all In links with too long or none Alt text and fix them;
In Links Rel attr length - This filter is useful for finding In links with no rel attr;
Identical In Links count – Get pages with particular number of Identical In Links. Identical links are links that have exactly the same attribute values – link type, anchor and alt text or rel attribute. Even if one of these attributes are slightly different then the links won’t be considered identical;
Out Links link type - Find all Out links of a particular type – CSS IMG/ IMG/ SCRIPT/ LINK/ HREF/ IFRAME/ FRAME/ BACKGROUND/ REDIRECT;
Out links Anchor text - Get all Out links with a particular anchor text;
Out links Alt text - Returns all Out links whose alt text contains/ starts with/ ends with a particular string
Out Links Rel attr - Find all Out links with a particular Rel attr – canonical, nofollow, noindex, …;
Out Links link type length - Retrieve all Out links with a particular length of the link type column;
Out links Anchor text length – Find all Out links with too long or none Anchor text and fix them;
Out links Alt text length - Alt text is recommended to be no more than 100 characters. Find all Out links with too long or none Alt text and fix them;
Out Links Rel attr length - This filter is useful for finding Out links with no rel attr;
Identical Out Links count - ...